jemalloc
Why does everyone who writes an allocater prepend it with their initials???
When writing software there is an unsung hero, memory allocation. At a high level there are two primary methods of memory management:
- Using a garbage collector for automatic memory management
- Using language primitives for manual memory management
Memory management is not something that needs to be taken in to account when using a language that has a garbage collector. The garbage collector is sitting idly by, watching everything you do, judging your careless declaration of objects and constantly cleaning up for you. Other languages that don't take advantage of a garbage collector are not so kind. Manual memory management is done in various ways throughout different languages and that is precisely the most recent topic we read about in my papers reading group at work. Specifically we read through A Scalable Concurrent malloc(3) Implementation for FreeBSD.
So, before diving in to some topics from the paper. How exactly does memory allocation work when you need to manage it yourself?
There are two primary memory regions for application code to use, the stack and the heap. The stack is where primitive data types are defined, think i32, bool, and f32 type variables.
The heap on the other hand is for more complex data types, a String or a struct is a good example of variables that get declared here. The heap needs to have memory allocated and deallocated.
C/C++ can use a method called malloc to perform memory allocation
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int *p1 = malloc(4*sizeof(int)); // allocates enough for an array of 4 int
int *p2 = malloc(sizeof(int[4])); // same, naming the type directly
int *p3 = malloc(4*sizeof *p3); // same, without repeating the type name
if(p1) {
for(int n=0; n<4; ++n) // populate the array
p1[n] = n*n;
for(int n=0; n<4; ++n) // print it back out
printf("p1[%d] == %d\n", n, p1[n]);
}
free(p1);
free(p2);
free(p3);
}
Calling free will deallocate the memory.
Rust, which I hear is all the rage due to its memory safety, doesn't require you to call malloc or free.
Instead, Rust uses the idea of ownership and borrowing which effectively will declare objects on the heap for you
and as soon as it leaves the scope Rust will call drop to perform automatic resource cleanup. This technique is also
known as RAII (Resource acquisition is initialization) and was popularized by C++.
fn main() {
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope s now over, and s is no
// longer valid
}
One of the reasons C has bugs due to 'memory safety' is often caused by calling free too much or too little, either leaving dangling pointers around or double-freeing. Wrangling around mallocs and frees all over the place can be quite unwieldy!
There are various other ways to allocate and deallocate memory both in C++ and Rust. I suggest giving the rust ownership doc a read if you're more interested in the intricacies of memory management in Rust. Or if you're a masochist the memory management C++ reference doc.
Now without further a'do, there are plenty of interesting ideas that went in to the creation of jemalloc.
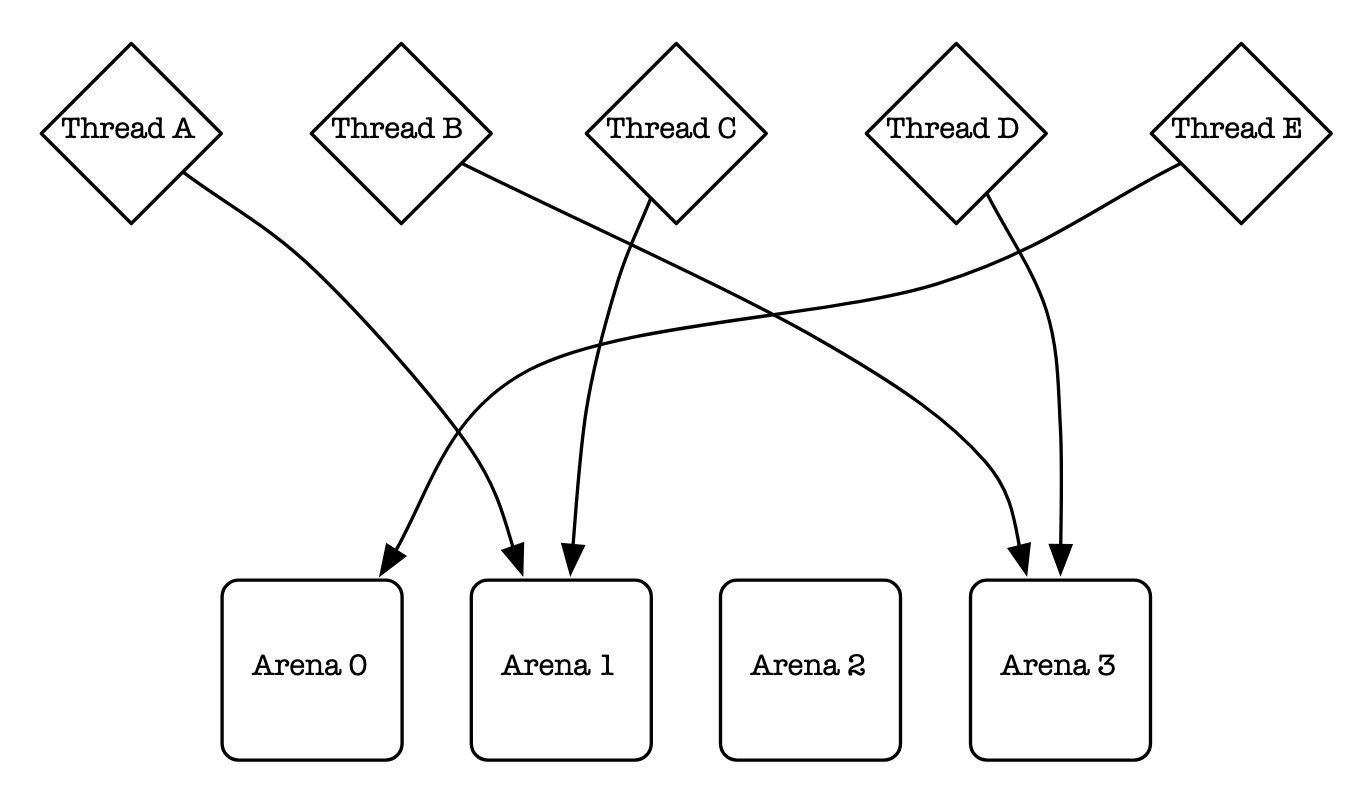
Arenas; two (or more) threads enter, one (or more) allocation leaves!
The primary reason for the creation of jemalloc is exactly as the paper title alludes to, scalability for multi-threaded/multi-processor systems. You see, back in the early aughts FreeBSD's default implementation of
malloc was lagging behind on performance for multi-threaded applications on multi-core systems. Hardware was improving so software needed to adapt. This version of malloc called phkmalloc would effectively
hold a global heap mutex wrapper around function calls.
Clearly this was not scalable as software
needed to catch up with the emergence of multi core systems and heavier usage of concurrency in application code. And thus, jemalloc was one memory allocator that found its way on to the scene
to help alleviate the problems with phkmalloc usage in highly concurrent settings.
Alright, cool, cool, cool. So how exactly does jemalloc account for multiple threads?
It utilizes a neat idea called an arena and then assigns threads to specific arenas.
Arena's are basically a data structure that maintains a large chunk of already allocated memory for an application to use.
To actually get memory from the operating system we need to use a syscall, usually mmap and sbrk are used.
Arena's will effectively call mmap to allocate a large pool of memory for our program to use continously, it will recycle memory as its free'ed.
Why do we need arenas if we can easily use a single function call to get memory from the operating system though? Why can't I just use mmap on every object
allocation? I guess if you wanted to, you could! But! There is a reason this is not a good idea, syscalls are very expensive.
F#$king syscalls, how do they work?
For example, lets say you have a small C++ program using good ol' malloc. Using the glibc version of malloc we are likely using the
dlmalloc implementation or something based on it.
int main(void) {
struct bar_t {
int a;
char b[512];
};
bar_t *p = (bar_t*)malloc(sizeof(bar_t));
if (p != nullptr) {
p->a = 100;
strcpy(p->b, "Planet Express");
}
free(p);
}
Underneath this call to malloc we make a few syscalls to mmap to create a memory arena. We can inspect with strace.
> gcc -o with_malloc main.cpp && strace -e mmap ./with_malloc
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7be8122bd000
mmap(NULL, 31200, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7be8122b5000
mmap(NULL, 2264656, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7be812000000
mmap(0x7be812028000, 1658880, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x28000) = 0x7be812028000
mmap(0x7be8121bd000, 360448, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1bd000) = 0x7be8121bd000
mmap(0x7be812216000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x215000) = 0x7be812216000
mmap(0x7be81221c000, 52816, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7be81221c000
mmap(NULL, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7be8122b2000
Taking a look at the dissassembly of mmap after loading this file in to gdb
(gdb) disas mmap
Dump of assembler code for function __GI___mmap64:
0x00007ffff79252f0 <+0>: endbr64
0x00007ffff79252f4 <+4>: test $0xfff,%r9d
0x00007ffff79252fb <+11>: jne 0x7ffff7925330 <__GI___mmap64+64>
0x00007ffff79252fd <+13>: push %rbp
0x00007ffff79252fe <+14>: mov %rsp,%rbp
0x00007ffff7925301 <+17>: push %r12
0x00007ffff7925303 <+19>: mov %ecx,%r12d
0x00007ffff7925306 <+22>: push %rbx
0x00007ffff7925307 <+23>: mov %rdi,%rbx
0x00007ffff792530a <+26>: test %rdi,%rdi
0x00007ffff792530d <+29>: je 0x7ffff7925350 <__GI___mmap64+96>
0x00007ffff792530f <+31>: mov %r12d,%r10d
0x00007ffff7925312 <+34>: mov %rbx,%rdi
0x00007ffff7925315 <+37>: mov $0x9,%eax
0x00007ffff792531a <+42>: syscall
We see the following lines
0x00007ffff7925315 <+37>: mov $0x9,%eax
0x00007ffff792531a <+42>: syscall
In this assembly the integer 9 $0x9 gets moved in to the %eax register. Afterwards syscall gets invoked which triggers a software interrupt, we know that 0x9 corresponds to mmap by taking a
look at the following syscall table. This process of putting a syscall
number in to a register and then initiating syscall will cause a context (or mode) switch from user space to kernel space.
Everything thats currently going on in the program execution needs to be effectively saved and then restored after the syscall is finished. This of course is incredibly expensive.
The state of the currently executing process must be saved so it can be restored when rescheduled for execution. The process state includes all the registers that the process may be using, especially the program counter, plus any other operating system specific data that may be necessary. This is usually stored in a data structure called a process control block (PCB) or switchframe. The PCB might be stored on a per-process stack in kernel memory (as opposed to the user-mode call stack), or there may be some specific operating system-defined data structure for this information. A handle to the PCB is added to a queue of processes that are ready to run, often called the ready queue.
And therefore, to mitigate this expensive operation from constantly happening malloc will use a memory arena. We allocate some large chunk(s) using mmap and
continue to use it over and over again attempting to defer any other calls to mmap if possible.
Back to jemalloc!
Now that a brief detour to better understand syscalls is over, lets get back to jemalloc. Using the same program above lets install jemalloc and link it.
> sudo apt install libjemalloc-dev && g++ -o with_jemalloc main.cpp -ljemalloc
And now lets take a look at the mmap calls with strace
> strace -e mmap ./with_jemalloc
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7971bf9cf000
mmap(NULL, 31200, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7971bf9c7000
mmap(NULL, 2987664, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7971bf600000
mmap(0x7971bf606000, 643072, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x6000) = 0x7971bf606000
mmap(0x7971bf6a3000, 53248, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0xa3000) = 0x7971bf6a3000
mmap(0x7971bf6b1000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0xb0000) = 0x7971bf6b1000
mmap(0x7971bf6b7000, 2238096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7971bf6b7000
mmap(NULL, 2264656, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7971bf200000
mmap(0x7971bf228000, 1658880, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x28000) = 0x7971bf228000
mmap(0x7971bf3bd000, 360448, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1bd000) = 0x7971bf3bd000
mmap(0x7971bf416000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x215000) = 0x7971bf416000
mmap(0x7971bf41c000, 52816, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7971bf41c000
mmap(NULL, 942344, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7971bf8e0000
mmap(0x7971bf8ee000, 507904, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0xe000) = 0x7971bf8ee000
mmap(0x7971bf96a000, 372736, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x8a000) = 0x7971bf96a000
mmap(0x7971bf9c5000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0xe4000) = 0x7971bf9c5000
mmap(NULL, 2275520, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7971bee00000
mmap(0x7971bee9a000, 1118208, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x9a000) = 0x7971bee9a000
mmap(0x7971befab000, 454656, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1ab000) = 0x7971befab000
mmap(0x7971bf01b000, 57344, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x21a000) = 0x7971bf01b000
mmap(0x7971bf029000, 10432, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7971bf029000
mmap(NULL, 127720, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7971bf5e0000
mmap(0x7971bf5e3000, 94208, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x3000) = 0x7971bf5e3000
mmap(0x7971bf5fa000, 16384, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1a000) = 0x7971bf5fa000
mmap(0x7971bf5fe000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1d000) = 0x7971bf5fe000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7971bf8de000
mmap(NULL, 16384, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7971bf8da000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7971bf5de000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE, -1, 0) = 0x7971bfa08000
mmap(NULL, 2097152, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE, -1, 0) = 0x7971bec00000
mmap(NULL, 2097152, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE, -1, 0) = 0x7971bea00000
mmap(NULL, 4194304, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_NORESERVE, -1, 0) = 0x7971be600000
Oh... well that's awkward. I just spent an extended period of time telling you about how slow syscalls are and this memory allocator
uses substantially more mmap calls for a simple executable. Remember how I said that jemalloc will use multiple arenas and assign threads to them?
Paying an upfront cost for more syscalls will allow us to create multiple memory arenas that threads can be assigned to.
Often times when building software there are tradeoffs, there's no such thing as free lunch. One of the primary tradeoffs in jemalloc is that you're paying a bit of an upfront cost
to generate more memory arenas. By having more arenas and most of the time having a single thread interact with a single arena we can avoid contention between threads and not have to worry about
holding locks throughout our memory allocation. This elimates are large bottleneck caused by phkmalloc and dlmalloc when using multiple threads.
To cache or not to cache (or to accidently invalidate the cache)
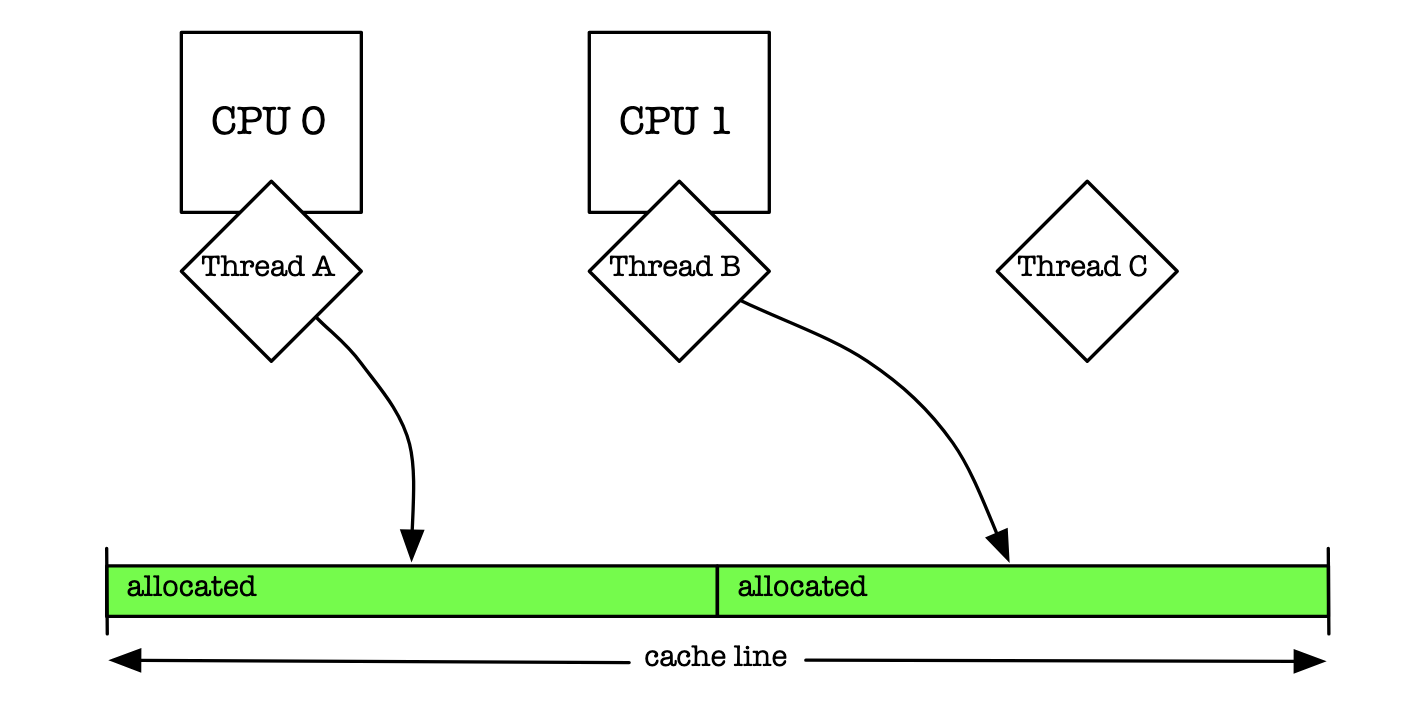
Let me illustrate another issue that having multiple arenas can solve as well. Let's imagine we have a single arena, but, within this arena we create multiple data structures to allocate and deallocate memory. Say a free list. Now we could potentially ease any lock contention by having multiple lists each with its own lock. This is precisely what is preposed in Memory allocation for long running server applications. Using multiple free lists each with their own dedicated locking mechanism proved to help with lock contention. It did not prove to scale adequetly with the latest and greatest hardware at the time though. This has been attributed to something known as false sharing. I believe the jemalloc paper calls this "cache sloshing".
Where main memory is accessed in a pattern that leads to multiple main memory locations competing for the same cache lines, resulting in excessive cache misses. This is most likely to be problematic for caches with associativity.
Okay but what is a cache line?
When the CPU puts data in its L1/L2/L3 cache registers it will go out to main memory (RAM) and fetch entire contigous chunks of data. This will save it from having to make round trips. The CPU likes when we store like data with each other at 64 byte offsets. That way it can fit nicely in to a cache line. See here if you're interested in reading more about how memory works.
In a perfect world we would have a single thread accessing each chunk in a cpu cache line
CPU CACHE LINE
┌───────────────────────────────────────────────────┐
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Block 1 │ │ Block 2 │ │ Block 3 │ │ Block 4 │ │
│──┼─────────┼─┼─────────┼─┼─────────┼─┼─────────┼──│
│ │ │ │ │ │ │ │ │ │
│ └──────▲──┘ └─▲───────┘ └─────▲───┘ └─▲───────┘ │
└─────────┼──────┼───────────────┼───────┼──────────┘
│ │ │ │
┌──┴──────┴───┐ ┌───┴───────┴─┐
│ │ │ │
│ Thread 1 │ │ Thread 2 │
│ │ │ │
└─────────────┘ └─────────────┘
Since cache lines in the CPU are fixed size chunks and given the fact that we can have two or more free lists. There is a good chance that our free lists will not be at the exact offsets required by the cache sizes.
CPU CACHE LINE
┌───────────────────────────────────────────────────┐
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Block 1 │ │ Block 2 │ │ Block 3 │ │ Block 4 │ │
│──┼─────────┼─┼─────────┼─┼─────────┼─┼─────────┼──│
│ │ │ │ │ │ │ │ │ │
│ └──────▲──┘ └─▲─────▲─┘ └─────▲───┘ └─────────┘ │
└─────────┼──────┼─────┼─────────┼──────────────────┘
│ │ │ │
┌──┴──────┴───┐ │ ┌───┼─────────┐
│ │ └─────┼ │
│ Thread 1 │ │ Thread 2 │
│ │ │ │
└─────────────┘ └─────────────┘
You see, even though the free lists are protected by mutexes there is nothing stopping one thread from working on another threads cached data. When this occurs the entire CPU cache line must be invalidated. The component which manages the caching mechanism does not know which division of the cache block is actually updated. It marks the whole block dirty, forcing a memory update to maintain cache coherency. This is a very expensive computation compared to a ‘write’ activity in the cache block.
Taking a look at the following rust code we can get a better idea of how this happens.
use std::thread;
use std::time::Instant;
static mut ARRAY: [i32; 100] = [0; 100];
fn compute(start: Instant, end: Instant) -> f64 {
let duration = end.duration_since(start);
duration.as_secs_f64() * 1000.0
}
fn expensive_function(index: usize) {
unsafe {
for _ in 0..100_000_000 {
ARRAY[index] += 1;
}
}
}
fn main() {
let first_elem = 0;
// This value is very close to 0 and will
// likely share the same cpu cache line.
let bad_elem = 1;
let good_elem = 99;
// Synchronous
let tp_begin1 = Instant::now();
expensive_function(first_elem);
expensive_function(bad_elem);
let tp_end1 = Instant::now();
// False sharing
let tp_begin2 = Instant::now();
let handle1 = thread::spawn(move || {
expensive_function(first_elem);
});
let handle2 = thread::spawn(move || {
expensive_function(bad_elem);
});
handle1.join().unwrap();
handle2.join().unwrap();
let tp_end2 = Instant::now();
// Multi-threaded without false sharing
let tp_begin3 = Instant::now();
let handle1 = thread::spawn(move || {
expensive_function(first_elem);
});
let handle2 = thread::spawn(move || {
expensive_function(good_elem);
});
handle1.join().unwrap();
handle2.join().unwrap();
let tp_end3 = Instant::now();
let time1 = compute(tp_begin1, tp_end1);
let time2 = compute(tp_begin2, tp_end2);
let time3 = compute(tp_begin3, tp_end3);
println!("False sharing: {:.6} ms", time2);
println!("Without false sharing: {:.6} ms", time3);
println!("Synchronous: {:.6} ms", time1);
}
And the output
False sharing: 717.221500 ms
Without false sharing: 433.996709 ms
Synchronous: 857.040209 ms
The code that forces a false sharing state will add an addition ~300 ms of time to the program execution. This is nearly as bad as just writing single threaded code.
As shown by the following malloc-test benchmark. We can see that jemalloc doesn't perform as well as dlmalloc on a single thread and slightly better than phkmalloc. As soon as multiple threads are in play, the
performance difference is astonishing. Recall that having multiple threads using a single arena can cause performance problems due to false sharing and contention. You'll notice that when jemalloc starts using
about 16 threads there is a bit of performance degredation. This is due to the system which ran this benchmark using 16 arenas.

Parting thoughts
Overall, A Scalable Concurrent malloc(3) Implementation for FreeBSD is a very good read, filled with a ton of systems programming wisdom.
I highly suggest giving it a read, there are so many more gems in there including how jemalloc deals with fragmentation, more benchmarks, and dealing with allocations that are larger that a suitable arena chunk can hold.
If looking at some code is also your thing I suggest taking a peek at the mozilla jemalloc implemenation too. Oh, and if you haven't figured it out by now the je in jemalloc stands for the authors name "Jason Evans", the dl in dlmalloc stands for the authors name Doug Lea, the phk in phkmalloc stands for "Poul-Henning Kamp" and so on and so forth. Basically all allocators use their author's initials.
As stated by Jason Evans
Allocator design and implementation has strong potential as the subject of career-long obsession, and indeed there are people who focus on this subject.
I personally have been enamored with the idea of memory allocators even before reading A Scalable Concurrent malloc(3) Implementation for FreeBSD. I'll likely be writing more about them in the near future.